This comprehensive guide provides step-by-step instructions for managing SQLite databases using Pandas DataFrames and SQLAlchemy in Python. It covers essential operations including setting up the database, creating tables, inserting, querying, merging, updating, and deleting data. With detailed examples and explanations, users can efficiently perform database operations while ensuring data integrity and accuracy.
1. Set up the Database and Create the Table.
- SQLite is a lightweight, file-based relational database management system that is widely used due to its simplicity and ease of integration with various programming languages, including Python.
- In this guide, we’ll walk through the steps to set up a SQLite database in Python using the SQLAlchemy library.
- Install Required Libraries: Before getting started, ensure you have SQLAlchemy installed. You can install it via pip:
$ pip install sqlalchemy ...... $ pip show sqlalchemy Name: SQLAlchemy Version: 1.4.39 Summary: Database Abstraction Library Home-page: https://www.sqlalchemy.org Author: Mike Bayer Author-email: [email protected] License: MIT Location: /Users/songzhao/anaconda3/lib/python3.11/site-packages Requires: greenlet Required-by:
- Import Required Modules:
from sqlalchemy import create_engine, MetaData, Table, Column, Integer, String
- Define Database Connection:
# Replace 'your_database.db' with the path to your SQLite database file database_path = 'your_database.db' engine = create_engine(f'sqlite:///{database_path}') - Define Table Structure:
# Define metadata metadata = MetaData() # Define table structure your_table_name = Table( 'your_table_name', metadata, Column('id', Integer, primary_key=True), Column('column1', String), Column('column2', String), # Add more columns as needed ) - Create the Table:
# Create the table in the database metadata.create_all(engine)
- Insert Data (Optional): If you want to insert data into the table immediately after creating it, you can do so using SQLAlchemy’s insert command:
# Example data to insert data = [ {'column1': 'value1', 'column2': 'value2'}, {'column1': 'value3', 'column2': 'value4'}, # Add more rows as needed ] # Insert data into the table with engine.connect() as conn: conn.execute(your_table_name.insert(), data) - Confirm Database Setup: You can verify that the database and table were created successfully by connecting to the SQLite database using a SQLite client or by querying the database programmatically.
# Verify table creation by fetching table names table_names = engine.table_names() print(table_names)
- Below is the full example source code that initializes an SQLite database and creates a table, to run other example source code in this article, you should first run the below code to create the table.
from sqlalchemy import create_engine, MetaData, Table, Column, Integer, String import pandas as pd engine = None # The get_db_connection() function is used to create a database connection. It initializes a SQLAlchemy engine if one does not already exist. def get_db_connection(): global engine # Check if the engine has been initialized if engine is None: # Replace 'your_database.db' with the path to your SQLite database file database_path = 'your_database.db' # Create a SQLAlchemy engine engine = create_engine(f'sqlite:///resource-files/{database_path}') return engine # The create_table() function defines the metadata and table structure, then creates the table in the database using SQLAlchemy's create_all() method. def create_table(your_table_name): # Define metadata metadata = MetaData() # Define table structure your_table_name = Table( your_table_name, metadata, Column('ID', Integer, primary_key=True), # Define the 'ID' column as the primary key Column('Name', String), # Define the 'Name' column Column('Age', Integer), # Define the 'Age' column # Add more columns as needed ) # Get the database connection engine = get_db_connection() # Create the table in the database metadata.create_all(engine) # Verify table creation by fetching table names table_names = engine.table_names() print(table_names) if __name__ == "__main__": # Call create_table function with the table name create_table('your_table_name') - After you run the above Python source code, it will create a SQLite database with the name your_database.db and create a table with the name your_table_name in the database. You can see this using SQLiteStudio.
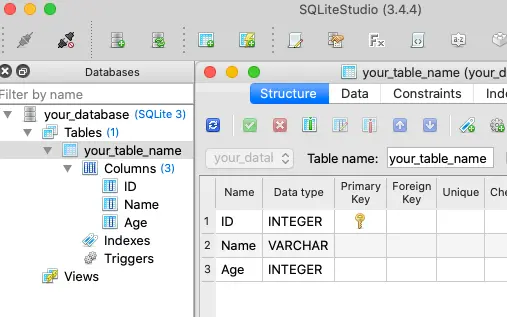
2. How to Insert Pandas DataFrame Data into an Existing SQLite Table.
- To insert data from a Pandas DataFrame into an existing SQLite table, you can use the `to_sql()` method of the DataFrame with the `if_exists=’append’` parameter.
- The `if_exists=’append’` parameter ensures that the data from the DataFrame is appended to the existing table. If the table doesn’t exist, it will be created.
- The `index=False` parameter ensures that the DataFrame index is not included in the SQLite table.
- Here’s how you can do it:
from sqlalchemy import create_engine, MetaData, Table, Column, Integer, String import pandas as pd engine = None # The get_db_connection() function is used to create a database connection. It initializes a SQLAlchemy engine if one does not already exist. def get_db_connection(): global engine # Check if the engine has been initialized if engine is None: # Replace 'your_database.db' with the path to your SQLite database file database_path = 'your_database.db' # Create a SQLAlchemy engine engine = create_engine(f'sqlite:///resource-files/{database_path}') return engine def insert_pandas_dataframe_data_into_existing_table(table_name): # Create a Pandas DataFrame with sample data data = { 'ID': [1, 2, 3], 'Name': ['Alice', 'Bob', 'Charlie'], 'Age': [25, 30, 35] } df = pd.DataFrame(data) engine = get_db_connection() # Insert DataFrame data into an existing SQLite table df.to_sql(table_name, engine, if_exists='append', index=False) # Confirm data insertion by reading from the SQLite table # Optional: Read data from the table to verify query = f'SELECT * FROM {table_name};' result_df = pd.read_sql(query, engine) print(result_df) if __name__ == "__main__": # Call create_table function with the table name # create_table('your_table_name') insert_pandas_dataframe_data_into_existing_table('your_table_name') - After running this code, the data from the DataFrame will be inserted into the specified existing SQLite table, and you can confirm the insertion by querying the table or printing its contents.
- Below are the outputs of the above Python source code.
ID Name Age 0 1 Alice 25 1 2 Bob 30 2 3 Charlie 35
3. How to Query SQLite Table to DataFrame.
- Below is a guide on how to query an SQLite table and convert the results into a Pandas DataFrame:
from sqlalchemy import create_engine, MetaData, Table, Column, Integer, String import pandas as pd engine = None # The get_db_connection() function is used to create a database connection. It initializes a SQLAlchemy engine if one does not already exist. def get_db_connection(): global engine # Check if the engine has been initialized if engine is None: # Replace 'your_database.db' with the path to your SQLite database file database_path = 'your_database.db' # Create a SQLAlchemy engine engine = create_engine(f'sqlite:///resource-files/{database_path}') return engine def query_sqlite_table_to_dataframe(table_name): engine = get_db_connection() # Step 2: Define your SQL query # Replace 'your_table_name' with the name of the SQLite table you want to query query = f'SELECT * FROM {table_name}' # Step 3: Execute the SQL query and fetch the results into a DataFrame df = pd.read_sql(query, engine) # Step 4: Optionally, close the database connection engine.dispose() # Step 5: Display or manipulate the DataFrame as needed print(df) if __name__ == "__main__": # Call create_table function with the table name # create_table('your_table_name') # insert_pandas_dataframe_data_into_existing_table('your_table_name') query_sqlite_table_to_dataframe('your_table_name') - The `pd.read_sql()` function executes the SQL query on the database engine and fetches the results into a Pandas DataFrame.
- Optionally, you can close the database connection using `engine.dispose()` after you have finished querying the database.
- You can then display or manipulate the DataFrame `df` as needed for further analysis or processing.
- Below are output when you run the above Python source code.
ID Name Age 0 1 Alice 25 1 2 Bob 30 2 3 Charlie 35
4. How to Update SQLite Table by Merging DataFrames in Python.
4.1 Introduce DataFrame’s merge() Function.
- Merging data from Pandas DataFrames into SQLite tables is a common task in data manipulation and analysis workflows. This process allows for seamless integration of data stored in DataFrames with existing SQLite databases, enabling efficient data management and analysis.
- Utilize Pandas’ powerful merging capabilities, such as the merge() function, to merge the existing DataFrame with the new DataFrame based on a common key. This ensures that existing records are updated with new values while preserving data integrity.
- The merge() function in Pandas is used to merge two or more DataFrames based on a common column or index. It combines rows from different DataFrames into a single DataFrame based on the specified merging strategy, such as inner, outer, left, or right join.
- Below is the syntax of the merge() function.
DataFrame.merge(right, how='inner', on=None, left_on=None, right_on=None, left_index=False, right_index=False, suffixes=('_x', '_y'), indicator=False, validate=None) - right: DataFrame or named Series. The DataFrame to be merged with.
- how: {‘left‘, ‘right‘, ‘outer‘, ‘inner‘}, default ‘inner‘. Specifies the type of merge to perform.
- on: Column name or list of column names to join on. Must be found in both DataFrames. If None and left_index and right_index are False, the intersection of the columns in the DataFrames will be used.
- left_on: Column name or list of column names to join on in the left DataFrame.
- right_on: Column name or list of column names to join on in the right DataFrame.
- left_index: bool, default False. Use the index from the left DataFrame as the join key(s).
- right_index: bool, default False. Use the index from the right DataFrame as the join key(s).
- suffixes: Tuple of (str, str), default (‘_x’, ‘_y’). Suffixes to apply to overlapping column names in the left and right DataFrame, respectively.
- indicator: bool or str, default False. Adds a column to the output DataFrame called “_merge” with information on the source of each row. If specified as a string, the column will have that string as its name.
- validate: str, optional. If specified, check if the merge is of a certain type. Can be “one_to_one“, “one_to_many“, “many_to_one“, or “many_to_many“.
- Returns: DataFrame. A DataFrame containing the merged data based on the specified merging strategy.
4.2 Pandas DataFrame merge() Function Example.
- In this example, the merge() function performs an inner join based on the ‘key‘ column, resulting in a DataFrame containing only the rows where the ‘key‘ value exists in both left_df and right_df.
import pandas as pd def how_to_use_dataframe_merge_function(): # Create left DataFrame with 'key' and 'value' columns left_df = pd.DataFrame({'key': ['A', 'B', 'C', 'D'], 'value': [1, 2, 3, 4]}) # Create right DataFrame with 'key' and 'value' columns right_df = pd.DataFrame({'key': ['B', 'D', 'E', 'F'], 'value': [5, 6, 7, 8]}) # Merge left and right DataFrames based on the 'key' column using an inner join merged_df = left_df.merge(right_df, on='key', how='inner') # Print the merged DataFrame print(merged_df) if __name__ == "__main__": how_to_use_dataframe_merge_function() - Output.
key value_x value_y 0 B 2 5 1 D 4 6
4.3 Use Pandas DataFrame merge() Function to Merge Data to SQLite Table Example.
- Example source code.
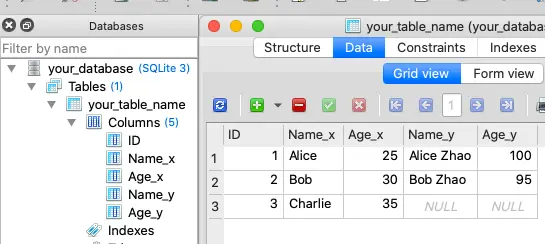
from sqlalchemy import create_engine, MetaData, Table, Column, Integer, String import pandas as pd engine = None # The get_db_connection() function is used to create a database connection. It initializes a SQLAlchemy engine if one does not already exist. def get_db_connection(): global engine # Check if the engine has been initialized if engine is None: # Replace 'your_database.db' with the path to your SQLite database file database_path = 'your_database.db' # Create a SQLAlchemy engine engine = create_engine(f'sqlite:///resource-files/{database_path}') return engine def update_sqlite_table_by_merge_dataframe(table_name): engine = get_db_connection() sql = f'SELECT * FROM {table_name}' # Step 2: Read the existing data from the SQLite table into a DataFrame existing_df = pd.read_sql(sql, engine) print('existing_df:') print(existing_df) # Step 3: Update the existing DataFrame with new data (for demonstration, replace with your actual update logic) # Create a new DataFrame with updated data updated_data = { 'ID': [1, 2], 'Name': ['Alice Zhao', 'Bob Zhao'], 'Age': [100, 95] } updated_df = pd.DataFrame(updated_data) print('updated_df:') print(updated_df) # Merge or join the existing DataFrame with the updated DataFrame based on a common key merged_df = existing_df.merge(updated_df, on='ID', how='left') print('merged_df:') print(merged_df) # Step 4: Write the merged DataFrame back to the SQLite table merged_df.to_sql(table_name, engine, if_exists='replace', index=False) if __name__ == "__main__": # Call create_table function with the table name # create_table('your_table_name') #insert_pandas_dataframe_data_into_existing_table('your_table_name') #query_sqlite_table_to_dataframe('your_table_name') update_sqlite_table_by_merge_dataframe('your_table_name') #how_to_use_dataframe_merge_function() - This function provides a straightforward approach to updating SQLite tables based on new data while maintaining the integrity of existing records through merging.
- After you run the above code, the SQLite database table will be changed to below.
5. How to Update Specified Column Value by Other Column Value.
- If you do not want to merge DataFrame value and just want to update the existing column value in the SQLite table, you can follow this example.
- Below is the example source code.
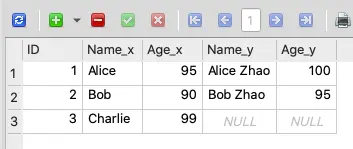
from sqlalchemy import create_engine, MetaData, Table, Column, Integer, String import pandas as pd engine = None # The get_db_connection() function is used to create a database connection. It initializes a SQLAlchemy engine if one does not already exist. def get_db_connection(): global engine # Check if the engine has been initialized if engine is None: # Replace 'your_database.db' with the path to your SQLite database file database_path = 'your_database.db' # Create a SQLAlchemy engine engine = create_engine(f'sqlite:///resource-files/{database_path}') return engine def update_sqlite_table_by_column(table_name, update_df): engine = get_db_connection() # Step 3: Update the 'Age_x' column in the SQLite table based on the 'Name_x' value from the DataFrame with engine.connect() as conn: for index, row in update_df.iterrows(): # Get the values to update name = row['Name_x'] # Assuming 'Name_x' is the column to use for updating new_age = row['Age_x'] # Replace 'Age_x' with the new age value from the DataFrame # Execute the SQL UPDATE statement update_query = f"UPDATE {table_name} SET Age_x = '{new_age}' WHERE Name_x = '{name}'" conn.execute(update_query) if __name__ == "__main__": # Example usage: # Define sample data and create a DataFrame data = {'Name_x': ['Alice', 'Bob', 'Charlie'], 'Age_x': [95, 90, 99]} df = pd.DataFrame(data) update_sqlite_table_by_column('your_table_name', df) - After you run the above example source code, the SQLite database table will be updated to below.
6. How to Delete SQLite Table Rows by DataFrame.
- To delete SQLite table rows using a DataFrame, you can achieve this by executing SQL DELETE statements based on the DataFrame data.
- Below is a Python function demonstrating how to delete rows from an SQLite table using information from a DataFrame:
from sqlalchemy import create_engine, MetaData, Table, Column, Integer, String import pandas as pd engine = None # The get_db_connection() function is used to create a database connection. It initializes a SQLAlchemy engine if one does not already exist. def get_db_connection(): global engine # Check if the engine has been initialized if engine is None: # Replace 'your_database.db' with the path to your SQLite database file database_path = 'your_database.db' # Create a SQLAlchemy engine engine = create_engine(f'sqlite:///resource-files/{database_path}') return engine def delete_rows_from_sqlite_table_by_dataframe(dataframe, table_name): # Establish a connection to the SQLite database engine = get_db_connection() # Delete rows from the SQLite table using the DataFrame data with engine.connect() as conn: for index, row in dataframe.iterrows(): # Formulate the SQL DELETE statement based on DataFrame data # Here we assume the DataFrame has a column 'ID' that uniquely identifies rows delete_query = f"DELETE FROM {table_name} WHERE ID = {row['ID']}" conn.execute(delete_query) # Close the database connection engine.dispose() if __name__ == "__main__": # Example usage for delete_rows_from_sqlite_table_by_dataframe(): # Define sample data and create a DataFrame data = {'ID': [1, 2]} df = pd.DataFrame(data) # Specify SQLite table name and database path table_name = 'your_table_name' # Call the function to delete rows from the SQLite table delete_rows_from_sqlite_table_by_dataframe(df, table_name)
7. Conclusion.
- By following these steps and ensuring data consistency and accuracy, you can efficiently manage table data in SQLite databases from Pandas DataFrames using SQLAlchemy.