It is very easy to find a web element’s XPath with Google Chrome, Firefox, Safari, Internet Explorer, Microsoft Edge inspector. And it is very important to get the best and correct XPath value. But how to do that? In this article, we will tell you how to get XPath from webelement in the correct way.
1. Absolute vs Relative XPath.
1.1 Absolute XPath.
- Absolute XPath like this /html/body/div[1]/div/div[1]/div[1]/div/article[1]/div/p[2]/a.
- It contains the below two disadvantages.
- It is too long.
- If one element changed then an ElementNotFound exception will be thrown in the Selenium WebDriver java code.
1.2 Relative XPath.
- Relative XPath like this //*[@id=’footer_nav’]/ul/li[3]/a. You should search for the latest id attribute in the web element’s XPath tree to get it. Watch the below screenshot.
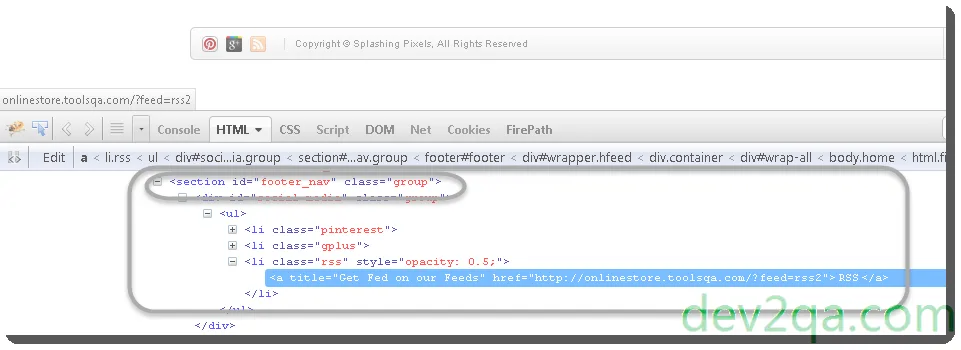
- You will find the last web element which has an id attribute in the DOM tree is ‘footer_nav‘. So an effective XPath should be //*[@id=’footer_nav’]/ul/li[3]/a.
- It contains the below advantages.
- Not too long.
- If the web elements before the id(footer_nav) in the DOM tree change, this XPath still works.
1.3 Difference Between Relative and Absolute XPath.
- Absolute XPath starts with a single slash ( / ). DOM engine will look for web elements beginning from the root node in the DOM tree.
- Relative XPath starts with a double slash ( // ). DOM engine will search for matching web elements anywhere in the XML DOM tree.
1.4 How To Use Single Slash “/” Or Double Slash “//” Correctly In XPath.
- Single slash ‘/’ exist anywhere means to find the DOM element instantly inside it’s parent.
- Double slash ‘//’ means to find any child or grand-child DOM element inside it’s parent.
- Following are examples of absolute and relative XPath.
- If the absolute XPath value is: /html/body/div[3]/div/div/footer/section[5]/div[@id=’social-media’]/ul/li[6]/a.
- You can use the below relative XPath to specify the same Html web element.
Relative XPath1: //*[@id=’social-media’]/ul/li[6]/a Relative XPath2: //body//footer/section[5]/div/ul/li[6]/a Relative XPath3: //body//section[5]/div/ul/li[6]/a
2. How To Write XPath For Dynamically Changed Html Web Element Attribute Value?
For those Html web elements whose attribute value is changed dynamically, we can use the following 3 functions to get it’s XPath value.
2.1 contains(@attrName, attrValue)
- @attrName: This is the attribute name of the web element.
- attrValue: This is the string contained by @attrName presented attribute’s value.
- In the following Html code, you can see the Html img tag’s src attribute’s value is a dynamic value, it is changed by each image.
<div class="profile_cont" itemtype="http://schema.org/Article" itemscope=""> <img src="http://www.dev2qa.com/wp-content/uploads/2017/05/show-html-code-snippet-for-the-search-button.png" itemprop="image"> </div> - So we can locate such a web element use the below XPath.
//img[contains(@src,'wp-content/uploads')]
2.2 starts-with(@attrName, attrValue)
- @attrName: This is the attribute name of the web element.
- attrValue: This is the started string of @attrName presented attribute’s value.
- For the same Html source code as section 2.1.
<div class="profile_cont" itemtype="http://schema.org/Article" itemscope=""> <img src="http://www.dev2qa.com/wp-content/uploads/2017/05/show-html-code-snippet-for-the-search-button.png" itemprop="image"> </div>
- We can get the Html img web element use the following XPath value.
//img[starts-with(@src,’http://www.dev2qa.com’)]
2.3 text().
- You can use this method to get a web element that exactly contains the text.
- For the below Html source code.
<p> As you can see from above java code, i use </p>
- We can use the below XPath to get the above Html p tag web element.
//p[text()='As you can see from above java code, i use']
3. How To Get Absolute Or Relative XPath In Google Chrome, Firefox, Safari, Microsoft Edge.
- Please read the article How To Find Web Element Using Web Browser Inspector to learn more.